victor_pv
Сб 29 апреля 2017 г., 19:52
Я добавляю SPI.dmasend и spi.Dmatransfer, как обсуждалось в другой ветке.
Теперь для этого мне нужно добавить несколько определений, и эти определения будут разными в зависимости от серии (такие вещи, как контроллер SPI1 DMA и канал для использования, IRQ, то же самое для SPI2, SPI3...SPI6).
Должен ли я поместить все эти определения в SPI.H файл, или, скорее, добавьте другой .H файл и включите его из SPI.час?
РЕДАКТИРОВАТЬ:
Я получил отличный Dmatransfer в режиме опроса (блокировки), аналогично ядрости Libmaple F1, по крайней мере для SPI1.
Протестировано с помощью SPI1 и SPI2.
Протестировано PITO с SDFAT для F1 (F1 File требует изменения #IFDEF для компиляции для этого ядра.)
Ему нужно работать, чтобы сделать его совместимым с большим количеством MCU и добавить неблокирующий режим с обратными вызовами.
Edit2:
Я добавил определения почти для всех серий и протестированного компиляции, но у меня не было возможности проверить функциональность, кроме F4.
У меня есть F1, так что я могу проверить это. Если у кого -то есть серия L0, L1, L4 или F3 и протестируйте его, дайте мне знать, если это работает.
РЕДАКТИРОВАТЬ3:
Новые исправления для серии L0 и L4, которые нуждались в дополнительных настройках.
Последняя рабочая версия в этом филиале:
https: // github.com/Victorpv/STM32Generic/Tree/Spi-DMA
Теперь для этого мне нужно добавить несколько определений, и эти определения будут разными в зависимости от серии (такие вещи, как контроллер SPI1 DMA и канал для использования, IRQ, то же самое для SPI2, SPI3...SPI6).
Должен ли я поместить все эти определения в SPI.H файл, или, скорее, добавьте другой .H файл и включите его из SPI.час?
РЕДАКТИРОВАТЬ:
Я получил отличный Dmatransfer в режиме опроса (блокировки), аналогично ядрости Libmaple F1, по крайней мере для SPI1.
Протестировано с помощью SPI1 и SPI2.
Протестировано PITO с SDFAT для F1 (F1 File требует изменения #IFDEF для компиляции для этого ядра.)
Ему нужно работать, чтобы сделать его совместимым с большим количеством MCU и добавить неблокирующий режим с обратными вызовами.
Edit2:
Я добавил определения почти для всех серий и протестированного компиляции, но у меня не было возможности проверить функциональность, кроме F4.
У меня есть F1, так что я могу проверить это. Если у кого -то есть серия L0, L1, L4 или F3 и протестируйте его, дайте мне знать, если это работает.
РЕДАКТИРОВАТЬ3:
Новые исправления для серии L0 и L4, которые нуждались в дополнительных настройках.
Последняя рабочая версия в этом филиале:
https: // github.com/Victorpv/STM32Generic/Tree/Spi-DMA
Пито
Солнце 30 апреля 2017 г. 12:06
Это измерение F407 Sdbench (168 МГц, Блэкз) для записи - SPI1 FREQ VS. RDWR Speed (Sammy Evo 8gb, Cl10), Sdfatex, Buff Size 512b:
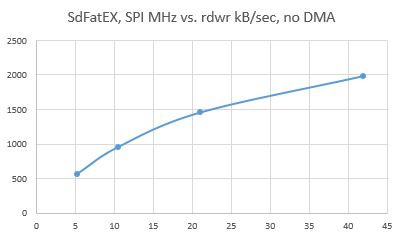
- Spi no dma rdwr Speed.JPG (18.55 киб) просмотрено 1723 раз
victor_pv
Солнце 30 апреля 2017 г., 3:21
Первая рабочая версия в этом филиале:
https: // github.com/Victorpv/STM32Generic/Tree/Spi-DMA
Отправил пиар Дэниелу на случай, если он захочет добавить его, чтобы больше людей могли начать тестирование/использовать его.
Я проверил это очень в основном, просто отправляя и получая данные в том же порту и сравнивая, что я получаю, когда я отправил. До сих пор тестирование только SPI1. Мне нужно найти булавки для SPI2 и SPI3 и повторить тесты.
Буду признателен за любые отзывы.
Основные изменения:
Добавление структур HDMA для каналов TX и RX.
Включение DMA1 и 2 периферийных часов во время .начинать
Ряд определений в .H Файл перечисляет, что применяется к комбинации контроллера DMA/потока к каждому порту.
Если в серии F4 есть несколько возможных потоков для каждого периферийного устройства, я просто выбрал то же самое, что HAL MX выбирает по умолчанию.
Нужный:
Поддержка других серий в определении
В функциях DMASEND и TRANSER FUNCTIONS FIFO и других настройках должны быть необязательными, поскольку они не применяются к F1 и F3, например, например,. Не уверен в лучшем способе реализации, мне действительно не нравится иметь кучу определений, брошенных в середине кода, поэтому может просто перенести настройки HDMA на отдельную функцию и, возможно, иметь все условные компиляции в этой единственной функции.
Поддержка обратного вызова. Мне нужно сначала добавить ISRS, которые могут управлять любым периферийным устройством и выяснить, какой из них нуждается в обслуживании (SPI1 до 6 в некоторых сериях).
Решить, должен ли все определения DMA быть в отдельном файле или сохранить их в SPI.час
https: // github.com/Victorpv/STM32Generic/Tree/Spi-DMA
Отправил пиар Дэниелу на случай, если он захочет добавить его, чтобы больше людей могли начать тестирование/использовать его.
Я проверил это очень в основном, просто отправляя и получая данные в том же порту и сравнивая, что я получаю, когда я отправил. До сих пор тестирование только SPI1. Мне нужно найти булавки для SPI2 и SPI3 и повторить тесты.
Буду признателен за любые отзывы.
Основные изменения:
Добавление структур HDMA для каналов TX и RX.
Включение DMA1 и 2 периферийных часов во время .начинать
Ряд определений в .H Файл перечисляет, что применяется к комбинации контроллера DMA/потока к каждому порту.
Если в серии F4 есть несколько возможных потоков для каждого периферийного устройства, я просто выбрал то же самое, что HAL MX выбирает по умолчанию.
Нужный:
Поддержка других серий в определении
В функциях DMASEND и TRANSER FUNCTIONS FIFO и других настройках должны быть необязательными, поскольку они не применяются к F1 и F3, например, например,. Не уверен в лучшем способе реализации, мне действительно не нравится иметь кучу определений, брошенных в середине кода, поэтому может просто перенести настройки HDMA на отдельную функцию и, возможно, иметь все условные компиляции в этой единственной функции.
Поддержка обратного вызова. Мне нужно сначала добавить ISRS, которые могут управлять любым периферийным устройством и выяснить, какой из них нуждается в обслуживании (SPI1 до 6 в некоторых сериях).
Решить, должен ли все определения DMA быть в отдельном файле или сохранить их в SPI.час
victor_pv
Солнце 30 апреля 2017 г. 3:24
Пито написал:Это измерение F407 (168 МГц, Blackze) для записи - SPI1 FREQ VS. RDWR Speed (Sammy Evo 8gb, Cl10), Sdfatex, Buff Size 512b:
Spi no dma rdwr Speed.JPG
Дважды проверили часы SPI с Лос-Анджелесом.
PS: я думаю это в SPI.CPP
Spi no dma rdwr Speed.JPG
Дважды проверили часы SPI с Лос-Анджелесом.
PS: я думаю это в SPI.CPP
if (settings.clock > apb_freq / 2) {
spiHandle.Init.BaudRatePrescaler = SPI_BAUDRATEPRESCALER_2;
} else if (settings.clock > apb_freq / 4) {
spiHandle.Init.BaudRatePrescaler = SPI_BAUDRATEPRESCALER_4;Даниэфф
Солнце 30 апреля 2017 г., 4:26 утра
Спасибо, я исправим настройки.часы.
Hal_dma_irqhandler () предназначен для обработки IRQ, проверьте сгенерированный куб STM32F4XX_IT.C: `extern" c "void dma2_stream3_irqhandler (void) () {hal_dma_irqhandler (&hdma_spi1_tx);} `(это также вызовет hdma_spi_rx->Xfercpltcallback (который устанавливается на слабый SPI_DMatransmitReceiveCplt () by hal_spi_transmitreceive_dma (что не идеально, кстати, я хочу пользовательские обратные вызовы))))))))
Мне было интересно, как вы справляетесь с запросами - потоки - каналы для каждой проблемы чипа
Hal_dma_irqhandler () предназначен для обработки IRQ, проверьте сгенерированный куб STM32F4XX_IT.C: `extern" c "void dma2_stream3_irqhandler (void) () {hal_dma_irqhandler (&hdma_spi1_tx);} `(это также вызовет hdma_spi_rx->Xfercpltcallback (который устанавливается на слабый SPI_DMatransmitReceiveCplt () by hal_spi_transmitreceive_dma (что не идеально, кстати, я хочу пользовательские обратные вызовы))))))))
Мне было интересно, как вы справляетесь с запросами - потоки - каналы для каждой проблемы чипа
victor_pv
Солнце 30 апреля 2017 г. 5:56 утра
Даниэфф написал:Спасибо, я исправим настройки.часы.
Hal_dma_irqhandler () предназначен для обработки IRQ, проверьте сгенерированный куб STM32F4XX_IT.C: `extern" c "void dma2_stream3_irqhandler (void) () {hal_dma_irqhandler (&hdma_spi1_tx);} `(это также вызовет hdma_spi_rx->Xfercpltcallback (который устанавливается на слабый SPI_DMatransmitReceiveCplt () by hal_spi_transmitreceive_dma (что не идеально, кстати, я хочу пользовательские обратные вызовы))))))))
Мне было интересно, как вы справляетесь с запросами - потоки - каналы для каждой проблемы чипа
Hal_dma_irqhandler () предназначен для обработки IRQ, проверьте сгенерированный куб STM32F4XX_IT.C: `extern" c "void dma2_stream3_irqhandler (void) () {hal_dma_irqhandler (&hdma_spi1_tx);} `(это также вызовет hdma_spi_rx->Xfercpltcallback (который устанавливается на слабый SPI_DMatransmitReceiveCplt () by hal_spi_transmitreceive_dma (что не идеально, кстати, я хочу пользовательские обратные вызовы))))))))
Мне было интересно, как вы справляетесь с запросами - потоки - каналы для каждой проблемы чипа
victor_pv
Солнце 30 апреля 2017 г. 6:43
Я запускаю некоторые скоростные тесты с SPI2, чтобы сравнить DMA с не DMMA Speeds.
Я запускаю только тесты на обоих с большим буфером 8 КБ.
8 КБ буфер
Скорость / Нет DMA / DMA
21 МБ / 8977.136US / 3127.777us
5.25 МБ / 17560.336US / 12490.117US
РЕДАКТИРОВАТЬ: Функция таблицы в PHPBB ужасна...
Использовал код, размещенный в другой ветке для меры США:
Я запускаю только тесты на обоих с большим буфером 8 КБ.
8 КБ буфер
Скорость / Нет DMA / DMA
21 МБ / 8977.136US / 3127.777us
5.25 МБ / 17560.336US / 12490.117US
РЕДАКТИРОВАТЬ: Функция таблицы в PHPBB ужасна...
Использовал код, размещенный в другой ветке для меры США:
elapsed = CpuGetTicks(); // Measure the 1ms delay
spi2.dmaTransfer(array_out, array_in, 8192);
//spi2.transfer(array_out, 8192);
elapsed = CpuGetTicks()- elapsed; // How many CPUTicks?
nanos = 5.9524 * elapsed; // Convert to nanosecondsДаниэфф
Солнце 30 апреля 2017 г. 6:56 утра
ОК на прерываниях.
К вашему сведению ваш код работает на моем F7.
Я думаю, что F2/F4/F7 одинаково (Stream+Channel), F0/F1/F3/L1 - это то же самое (канал), L0/L4 одинаково (канал+запрос).
Кроме того, если инженеры STM32 были хороши, нам повезло, и они всегда на одном (SPI1_TX всегда на DMA2_Stream3 или DMA3_Stream5 на F2/F4/F7...)
К вашему сведению ваш код работает на моем F7.
Я думаю, что F2/F4/F7 одинаково (Stream+Channel), F0/F1/F3/L1 - это то же самое (канал), L0/L4 одинаково (канал+запрос).
Кроме того, если инженеры STM32 были хороши, нам повезло, и они всегда на одном (SPI1_TX всегда на DMA2_Stream3 или DMA3_Stream5 на F2/F4/F7...)
victor_pv
Солнце 30 апреля 2017 г. 7:04
Я получаю начинку, они в значительной степени копируют/вставьте аппаратные блоки между сериями, так что, надеюсь, они одинаковы, но если нет, я не думаю, что это слишком много проблем с добавлением, так как в справочных руководствах есть хороший таблица для каналов DMA.
Рад узнать, работает ли на F7. У меня есть один, который я получил в прошлом году, чтобы бесплатно получить пыль на полке, теперь могу использовать его для некоторого использования
Рад узнать, работает ли на F7. У меня есть один, который я получил в прошлом году, чтобы бесплатно получить пыль на полке, теперь могу использовать его для некоторого использования
Пито
Солнце 30 апреля 2017 г. 11:05
21 МБ / 8977.136US / 3127.777us
Теоретическое время передачи DMA для большого буфера на 8192 байтов при скорости SPI 21 МГц составляет 3120.762US
Хм, я хочу в качестве теста, чтобы заменить получение в SDFAT SDSpidriver.H с Dmatransfer
Хм, я хочу в качестве теста, чтобы заменить получение в SDFAT SDSpidriver.H с Dmatransfer
uint8_t receive(uint8_t* buf, size_t n) {
SPI.dmaTransfer( buf, buf, n);
// SPI.dmaTransfer( 0, buf, n);
// for (size_t i = 0; i < n; i++) {
// buf[i] = SPI.transfer(0XFF);
// }
return 0;
}michael_l
Солнце 30 апреля 2017 г. 12:45
Victor_pv: Хорошая работа, я могу проверить, когда у меня есть больше свободного времени. Я постараюсь сначала работать на бортовой вспышке, работая.
Есть ли смысл в создании небольшого тестового набора для SPI и SPI DMA между SPI1 и SPI2, чтобы проверить, как он работает ?
Есть ли смысл в создании небольшого тестового набора для SPI и SPI DMA между SPI1 и SPI2, чтобы проверить, как он работает ?
victor_pv
Солнце 30 апреля 2017 г. 13:29
Пито написал:
SPI.dmaTransfer( buf, buf, n);
// SPI.dmaTransfer( 0, buf, n);
Пито
Солнце 30 апреля 2017 г. 13:31
Я обновил результаты.. Примерно в 2 раза быстрее WR/Rd.
Да, нам нужен нулевый буфер
Это измерение F407 Sdbench (168 МГц, Блэкз) для записи - SPI1 FREQ VS. RDWR Speed (Sammy Evo 8gb, CL10), Sdfatex, размер буфера 512bytes:
Да, нам нужен нулевый буфер
Это измерение F407 Sdbench (168 МГц, Блэкз) для записи - SPI1 FREQ VS. RDWR Speed (Sammy Evo 8gb, CL10), Sdfatex, размер буфера 512bytes:
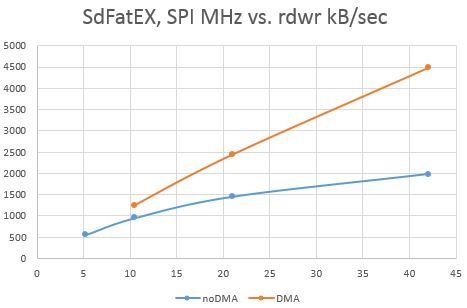
- SPI против RDWR Speed.JPG (26.6 киб) просмотрено 469 раз
victor_pv
Солнце 30 апреля 2017 г. 13:32
michael_l написал:Victor_pv: Хорошая работа, я могу проверить, когда у меня есть больше свободного времени. Я постараюсь сначала работать на бортовой вспышке, работая.
Есть ли смысл в создании небольшого тестового набора для SPI и SPI DMA между SPI1 и SPI2, чтобы проверить, как он работает ?
Есть ли смысл в создании небольшого тестового набора для SPI и SPI DMA между SPI1 и SPI2, чтобы проверить, как он работает ?
Пито
Солнце 30 апреля 2017 г. 14:13
@victor, ОК, изменилось здесь, и это работает. Обновлено выше диаграммы, так как скорость чтения сейчас намного выше +20%
Кстати, что такое MINC = 1 в SPI.dmasend (const_cast<uint8_t*>(buf), n, 1); Приращение памяти??
Кстати, что такое MINC = 1 в SPI.dmasend (const_cast<uint8_t*>(buf), n, 1); Приращение памяти??
Пито
Солнце 30 апреля 2017 г. 14:40
Если библиотека SDFAT была изменена для переключения потока для MS при ожидании задержки, я предполагаю, что это могло бы дать еще одну хорошую часть времени процессора обратно на эскизы, которые пишут. Мой игрок WAV только читает, я не думаю, что в чтениях много задержки, верно?
Вам нужно проверить Sdbench на F1? Я могу сделать..
victor_pv
Солнце 30 апреля 2017 г. 14:54
Пито написал:@victor, ОК, изменилось здесь, и это работает. Обновлено выше диаграммы, так как скорость чтения сейчас намного выше +20%
Кстати, что такое MINC = 1 в SPI.dmasend (const_cast<uint8_t*>(buf), n, 1); Приращение памяти??
Кстати, что такое MINC = 1 в SPI.dmasend (const_cast<uint8_t*>(buf), n, 1); Приращение памяти??
Пито
Солнце 30 апреля 2017 г. 15:54
Мой игрок WAV только читает, я не думаю, что в чтениях много задержки, верно?
Задержки записи с помощью SDCARDS огромные, 5-250 мс, обычно 3-50 мс все время, случайное явление..
С моими вышеупомянутыми экспериментами я не трогал файл драйвера SDFAT SDFATM32F1 (даже я провел несколько часов с ним..).
Я просто заменил функции приема и отправки (см. Выше) в SDSpidriver.
Это большой Q, нужен ли нам файл драйвера F1 или нет. Когда вы устанавливаете ex mode и режим DMA Hardwired, вам не нужна то, что SDSpistm32f1, я думаю.
Так что просто в шписдривере из строки 231+ 73+ ifdefs вокруг eCeat () и send ()..
По причинам совместимости я попытался переименовать SDSPISTM32F1 в SDSPISTM32F4, установил __STM2F4__ внутри (нам нужен этот флаг в флагах) и испортился с внутренними..Поскольку проблема с нулевым указателем), поэтому я остановился и лучше вошел прямо в драйвер sdspidriver.
Когда будет sdspistm32f4 с __stm32f4__ внутри, теперь он может работать сейчас. Вы также должны играть с __stm32f4__ в SDFATCONFIG.H тоже (может быть, 2-3x). Внутри много беспорядка из -за AVR и различных моди.
Но есть только 1 режим, который работает с F1/4 - это расширенный режим с DMA.
С моими вышеупомянутыми экспериментами я не трогал файл драйвера SDFAT SDFATM32F1 (даже я провел несколько часов с ним..).
Я просто заменил функции приема и отправки (см. Выше) в SDSpidriver.
Это большой Q, нужен ли нам файл драйвера F1 или нет. Когда вы устанавливаете ex mode и режим DMA Hardwired, вам не нужна то, что SDSpistm32f1, я думаю.
Так что просто в шписдривере из строки 231+ 73+ ifdefs вокруг eCeat () и send ()..
По причинам совместимости я попытался переименовать SDSPISTM32F1 в SDSPISTM32F4, установил __STM2F4__ внутри (нам нужен этот флаг в флагах) и испортился с внутренними..Поскольку проблема с нулевым указателем), поэтому я остановился и лучше вошел прямо в драйвер sdspidriver.
Когда будет sdspistm32f4 с __stm32f4__ внутри, теперь он может работать сейчас. Вы также должны играть с __stm32f4__ в SDFATCONFIG.H тоже (может быть, 2-3x). Внутри много беспорядка из -за AVR и различных моди.
Но есть только 1 режим, который работает с F1/4 - это расширенный режим с DMA.
Racemaniac
Солнце 30 апреля 2017 г. 16:26
Пито написал:Мой игрок WAV только читает, я не думаю, что в чтениях много задержки, верно?
Задержки записи с помощью SDCARDS огромные, 5-250 мс, обычно 3-50 мс все время, случайное явление..
victor_pv
Солнце 30 апреля 2017 г. 16:53
Реданьяк написал:Пито написал:Мой игрок WAV только читает, я не думаю, что в чтениях много задержки, верно?
Задержки записи с помощью SDCARDS огромные, 5-250 мс, обычно 3-50 мс все время, случайное явление..
Racemaniac
Солнце 30 апреля 2017 г., 17:01
victor_pv написал:Если ваш выходной драйвер тоже не использует DMA, вы должны изучить его, особенно вы используете для него драйверы.
Какую жирную библиотеку вы используете с F411?
Какую жирную библиотеку вы используете с F411?
Chismicro
Солнце 30 апреля 2017 г., 17:34
Может ли кто -нибудь из вас добавить простой набросок рабочих примеров?
Я сделал что -то для I2s без DMA.
Я сделал что -то для I2s без DMA.
Пито
Солнце 30 апреля 2017 г., 17:40
Задержки SDCARD - вы можете проверить задержки с помощью SDBench. По мере того, как Micros () хорошо работает сегодня, вы увидите цифры - максимальности, мин, средний, в то время как вы пишете/читаете. Больший файл, который вы пишете самые длинные задержки, с которыми вы можете столкнуться.
Задержки записи огромны, так как SDCARD делает свою домашнюю работу (то есть и т. Д.). Задержки читать минимальны, около 1.5 мс обычно. Таким образом, критическое написание - т.е. для 1 МБ/с. Устойчивые написать вам необходимость, как правило, ~ 100 КБ большого буфера FIFO (сдача на 100 мс). Существует тема «Loggard с FIFO», которая подробно рассказывает об этом подробно.
Здесь, например:
Задержки записи огромны, так как SDCARD делает свою домашнюю работу (то есть и т. Д.). Задержки читать минимальны, около 1.5 мс обычно. Таким образом, критическое написание - т.е. для 1 МБ/с. Устойчивые написать вам необходимость, как правило, ~ 100 КБ большого буфера FIFO (сдача на 100 мс). Существует тема «Loggard с FIFO», которая подробно рассказывает об этом подробно.
Здесь, например:
write speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
4381.84,16924,108,115
4508.28,8079,108,112
Starting read test, please wait.
read speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
3816.55,2083,133,133
3819.47,1322,133,133Даниэфф
Солнце 30 апреля 2017 г. 18:20
victor_pv написал:@Daniel, в ваших определениях для MOSI, MISO и т. Д., Вы используете порты PB4 и PB5, один из них тот же используется для SWO. Я узнал, потому что я должен использовать SWO из -за отсутствия USB в этой доске.
Есть ли причина по умолчанию, а не в другой набор булавок? Если нет причин или выгоды, я бы посоветовал изменить его, чтобы SWO можно было использовать одновременно с SPI1. Не очень важно для большинства людей, но большое раздражение для моей доски 407.
Есть ли причина по умолчанию, а не в другой набор булавок? Если нет причин или выгоды, я бы посоветовал изменить его, чтобы SWO можно было использовать одновременно с SPI1. Не очень важно для большинства людей, но большое раздражение для моей доски 407.
victor_pv
Солнце 30 апреля 2017 г. 18:28
Да, это на доске F407VET, не черное, но синее, но я не думаю, что стоит сделать вариант для него в одиночку, и, возможно, в моей вспышке SPI тоже связана с этими булавками.
Тогда я просто обойду его.
Тогда я просто обойду его.
victor_pv
Солнце 30 апреля 2017 г. 18:29
Реданьяк написал:victor_pv написал:Если ваш выходной драйвер тоже не использует DMA, вы должны изучить его, особенно вы используете для него драйверы.
Какую жирную библиотеку вы используете с F411?
Какую жирную библиотеку вы используете с F411?
Racemaniac
Солнце 30 апреля 2017 г. 18:31
victor_pv написал:Реданьяк написал:victor_pv написал:Если ваш выходной драйвер тоже не использует DMA, вы должны изучить его, особенно вы используете для него драйверы.
Какую жирную библиотеку вы используете с F411?
Какую жирную библиотеку вы используете с F411?
Даниэфф
Солнце 30 апреля 2017 г. 18:43
Re: Null Send Buffer в dmatransfer (): разве это не будет просто получать? Как в (в настоящее время отсутствует) `uint8_t spiclass :: dmareceive (uint8_t *receatbuf, uint16_t длина)`?, и используйте hal_spi_receive_dma
Пито
Солнце 30 апреля 2017 г. 22:37
SPI всегда отправляет и получает параллельно.
victor_pv
Солнце 30 апреля 2017 г. 22:50
Даниэфф написал:Re: Null Send Buffer в dmatransfer (): разве это не будет просто получать? Как в (в настоящее время отсутствует) `uint8_t spiclass :: dmareceive (uint8_t *receatbuf, uint16_t длина)`?, и используйте hal_spi_receive_dma
Пито
Пн, 1 мая 2017 г., 11:31
Пытаясь построить Sdbench для Maplemini, я получаю
SPI\src\SPI.cpp:15:2: error: 'DMA_Stream_TypeDef' was not declared in this scope
DMA_Stream_TypeDef *_StreamTX;victor_pv
Пн, 1 мая 2017 г. 14:02
Пито написал:Пытаясь построить Sdbench для Maplemini, я получаю
SPI\src\SPI.cpp:15:2: error: 'DMA_Stream_TypeDef' was not declared in this scope
DMA_Stream_TypeDef *_StreamTX;victor_pv
Пн, 1 мая 2017 г. 16:36
Даниэфф написал:ОК на прерываниях.
К вашему сведению ваш код работает на моем F7.
Я думаю, что F2/F4/F7 одинаково (Stream+Channel), F0/F1/F3/L1 - это то же самое (канал), L0/L4 одинаково (канал+запрос).
Кроме того, если инженеры STM32 были хороши, нам повезло, и они всегда на одном (SPI1_TX всегда на DMA2_Stream3 или DMA3_Stream5 на F2/F4/F7...)
К вашему сведению ваш код работает на моем F7.
Я думаю, что F2/F4/F7 одинаково (Stream+Channel), F0/F1/F3/L1 - это то же самое (канал), L0/L4 одинаково (канал+запрос).
Кроме того, если инженеры STM32 были хороши, нам повезло, и они всегда на одном (SPI1_TX всегда на DMA2_Stream3 или DMA3_Stream5 на F2/F4/F7...)
Даниэфф
Вторник 2 мая 2017 г. 15:36
Я думаю, что #define spi1_streamtx 1_channel3... вещи должны быть в центральном STM32_DMA.час.
Таким образом, будет проще увидеть, что использует SPI/SDIO/I2S, и проверить конфликты.
Таким образом, будет проще увидеть, что использует SPI/SDIO/I2S, и проверить конфликты.
victor_pv
Вторник 2 мая 2017 г. 16:44
Даниэфф написал:Я думаю, что #define spi1_streamtx 1_channel3... вещи должны быть в центральном STM32_DMA.час.
Таким образом, будет проще увидеть, что использует SPI/SDIO/I2S, и проверить конфликты.
Таким образом, будет проще увидеть, что использует SPI/SDIO/I2S, и проверить конфликты.
Пито
Вторник 02 мая 2017 г., 17:45
Тестирование SPI F1 с SDFAT на Maple Mini.
Это с STM32F1 (SDFATEX, DMA, 36 МГц SPI) Libmaple Core
Это с STM32F1 (SDFATEX, DMA, 36 МГц SPI) Libmaple Core
File size 6 MB
Buffer size 512 bytes
Starting write test, please wait.
write speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
3533.34,25083,136,143
3594.74,15522,136,141
Starting read test, please wait.
read speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
3257.12,1548,155,156
3258.89,1359,155,156
Done
Type any character to startПито
Вторник 2 мая 2017 г., 18:20
С более медленными часами
write speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
1946.03,26753,252,261
1976.16,12442,252,257
Starting read test, please wait.
read speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
774.14,2547,658,659
774.04,2546,658,659
Donevictor_pv
Вторник 2 мая 2017 г., 19:06
Пито написал:С более медленными часами
write speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
1946.03,26753,252,261
1976.16,12442,252,257
Starting read test, please wait.
read speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
774.14,2547,658,659
774.04,2546,658,659
DoneПито
Вторник 2 мая 2017 г., 19:20
Задержка MIN - это в основном время перенести блок (512bytes). Соотношение 2.6, это умножено на 774 - 2000.
victor_pv
Вторник 02 мая 2017 г. 8:03 вечера
Пито написал:Задержка MIN - это в основном время перенести блок (512bytes). Соотношение 2.6, это умножено на 774 - 2000.
Пито
Вторник 2 мая 2017 г. 11:06 вечера
Приведенные выше значения чтения были с
buf[i] = SPI.transfer(0XFF);victor_pv
Ср. 3 мая 2017 г. 12:05
Пито написал:
Приведенные выше значения чтения были с
Приведенные выше значения чтения были с
buf[i] = SPI.transfer(0XFF);Пито
Ср. 3 мая 2017 г. 12:18
Для Maple Mini. Редактор Eclipse показывает это.. Так что, может быть, ложный положительный
victor_pv
Ср. 3 мая 2017 г. 12:25
Пито написал:Для Maple Mini. Редактор Eclipse показывает это.. Так что, может быть, ложный положительный
Пито
Ср. 3 мая 2017 г. 8:06 утра
Нет изменений с новейшим SPI и F1 на MM..
Читать не работает здесь с F1..
С F4 это работает.
Читать не работает здесь с F1..
С F4 это работает.
AG123
Ср. 3 мая 2017 г. 8:28
OT: Казалось, у меня были некоторые «проблемы с проводами», играя с Sdfatex на оригинальном ядре F1 Libmaple, я не уверен, что иногда сама провода может быть в конце концов, чтобы все это было 
http: // www.STM32duino.com/viewtopic.PHP ... 420#P27420
http: // www.STM32duino.com/viewtopic.PHP ... 420#P27420
victor_pv
Ср. 3 мая 2017 г. 13:49
Пито написал:Нет изменений с новейшим SPI и F1 на MM..
Читать не работает здесь с F1..
С F4 это работает.
Читать не работает здесь с F1..
С F4 это работает.
Пито
Ср. 3 мая 2017 г. 16:59
Правильный. Я не могу читать файл, работающий в Sdbench с F1 с DMA (Maplemini).
victor_pv
Ср. 3 мая 2017 г., 18:24
Пито написал:Правильный. Я не могу читать файл, работающий в Sdbench с F1 с DMA (Maplemini).
victor_pv
Чт, 04 мая 2017 2:29
Я не вижу ничего плохого с кодом F1.
Мне придется подключить доску в SDCard и Jlink и посмотреть, что я могу найти.
Мне придется подключить доску в SDCard и Jlink и посмотреть, что я могу найти.
Пито
Чт, 04 мая 2017 12:56
Должно быть что -то не так с версией F1 SPI DMA.
Это Sdbench с F1 DMA Libmaple:
Это Sdbench с F1 DMA Libmaple:
write speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
1972.26,21385,251,258
1996.68,8447,251,255
1987.15,11002,251,256
Starting read test, please wait.
read speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
2044.86,1767,248,249
2046.53,1766,248,249
2046.53,1765,248,249victor_pv
Чт, 04 мая 2017 13:48
Пито написал:Должно быть что -то не так с версией F1 SPI DMA.
Это Sdbench с F1 DMA Libmaple:
Это Sdbench с F1 DMA Libmaple:
write speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
1972.26,21385,251,258
1996.68,8447,251,255
1987.15,11002,251,256
Starting read test, please wait.
read speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
2044.86,1767,248,249
2046.53,1766,248,249
2046.53,1765,248,249Пито
Чт, 04 мая 2017 г. 16:18
Это ядро Дэниела, а не DMA:
write speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
368.38,90734,1302,1365
375.24,90747,1302,1352
377.19,366597,1302,1354
Starting read test, please wait.
read speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
error: data checkДаниэфф
Чт, 04 мая 2017 г., 17:39
Здесь: http: // www.STM32duino.com/viewtopic.PHP ... 038#P27339
У этого нет возврата: `uint8_t sdspialtdriver :: checte () {`
И изменить это:
У этого нет возврата: `uint8_t sdspialtdriver :: checte () {`
И изменить это:
SPI.transfer(const_cast(buf), n); Пито
Чт, 04 мая 2017 г., 17:57
С изменениями (все ниже с Сандиск) - Даниэль F1 NO DMA, Sandisk Fresh Formatted
write speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
781.69,22685,640,651
790.46,12851,640,645
792.59,11424,640,643
Starting read test, please wait.
read speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
774.18,1916,658,659
774.18,1917,658,659
774.18,1917,658,659
Даниэфф
Чт, 04 мая 2017 г., 19:26
С DMA он, кажется, работает, если в конце `uint8_t spiclass :: dmasend (uint8_t *anpermitbuf, uint16_t length, bool minc) {` Я положил `hal_dma_deinit (bool minc) {` `hal_dma_deinit (&hdma_spi_tx); `.
Странный.
Странный.
Пито
Чт, 04 мая 2017 г., 19:51
Я пытался, но негативно..
victor_pv
Пт 5 мая 2017 г. 13:28
Пито написал:Я пытался, но негативно..
Пито
Пт, 5 мая 2017 г. 14:25
Будьте осторожны с DANIEL's F1 DMA OFF - она пишет, но файловая система стала поврежденной - выходной файл SDBench содержит «ABCD.."Строки, так что это легко проверить. Всегда старайтесь открыть файл на SDCARD после SDBench под Win/Lin.
victor_pv
Пт, 5 мая 2017 г. 18:43
Пито написал:Будьте осторожны с DANIEL's F1 DMA OFF - она пишет, но файловая система стала поврежденной - выходной файл SDBench содержит «ABCD.."Строки, так что это легко проверить. Всегда старайтесь открыть файл на SDCARD после SDBench под Win/Lin.
victor_pv
Сб, 6 мая 2017 г. 18:06
Все еще не выяснил, почему F1 повреждает SDCARD, но до сих пор я обнаружил, что F1 HAL MX имеет то, что мне кажется, как ошибка на этой функции:
Hal_spi_transmitreceive_dma
Во всех остальных сериях есть этот комментарий, за которым следует две строки, которые делают то, что говорится в комментарии, но в F1 есть комментарий, но не код, который действительно делает это:
Hal_spi_transmitreceive_dma
Во всех остальных сериях есть этот комментарий, за которым следует две строки, которые делают то, что говорится в комментарии, но в F1 есть комментарий, но не код, который действительно делает это:
/* Set the SPI Tx DMA transfer complete callback as NULL because the communication closing
is performed in DMA reception complete callback */
hspi->hdmatx->XferHalfCpltCallback = NULL;
hspi->hdmatx->XferCpltCallback = NULL;Пито
Сб 6 мая 2017 г., 21:27
Я бы начну с DMA, так как это тоже испортилось. Может быть, параметры SPI устанавливаются неправильно?
victor_pv
Сб, 6 мая 2017 г., 21:50
Пито написал:Я бы начну с DMA, так как это тоже испортилось. Может быть, параметры SPI устанавливаются неправильно?
Даниэфф
Солнце 07 мая 2017 г. 13:58
Добавлен тестовый код в примеры/тестирование/Spiselftest платы
Протестировано на Maple Mini. Подключите штифты SPI1 к SPI2 (они установлены как мастер и раб). Он отправляет с помощью SPI.Передача, SPI.dmatransfer (без нулевого sendbuffer), spi.dmasend. Затем он пишет отправленные и полученные байты на Master/Slave SPI в сериал.
Наблюдения: связь, пока DMASEND не работает нормально. чем поврежден.
Если DMASEND прокомментируется, но используется Dmatransfer, Whying работает нормально (почти...).
Фактически внедрение DMA IRQ (с низким приоритетом!!! иначе Spi salve забивается), похоже, решает проблему. Но тогда HAL_DMA_POLLFORTRANSFER не работает, и вам нужно установить пользовательские флаги.
Протестировано на Maple Mini. Подключите штифты SPI1 к SPI2 (они установлены как мастер и раб). Он отправляет с помощью SPI.Передача, SPI.dmatransfer (без нулевого sendbuffer), spi.dmasend. Затем он пишет отправленные и полученные байты на Master/Slave SPI в сериал.
Наблюдения: связь, пока DMASEND не работает нормально. чем поврежден.
Если DMASEND прокомментируется, но используется Dmatransfer, Whying работает нормально (почти...).
Фактически внедрение DMA IRQ (с низким приоритетом!!! иначе Spi salve забивается), похоже, решает проблему. Но тогда HAL_DMA_POLLFORTRANSFER не работает, и вам нужно установить пользовательские флаги.
victor_pv
Солнце 07 мая 2017 г. 14:43
Даниэфф написал:Добавлен тестовый код в примеры/тестирование/Spiselftest платы
Протестировано на Maple Mini. Подключите штифты SPI1 к SPI2 (они установлены как мастер и раб). Он отправляет с помощью SPI.Передача, SPI.dmatransfer (без нулевого sendbuffer), spi.dmasend. Затем он пишет отправленные и полученные байты на Master/Slave SPI в сериал.
Наблюдения: связь, пока DMASEND не работает нормально. чем поврежден.
Если DMASEND прокомментируется, но используется Dmatransfer, Whying работает нормально (почти...).
Фактически внедрение DMA IRQ (с низким приоритетом!!! иначе Spi salve забивается), похоже, решает проблему. Но тогда HAL_DMA_POLLFORTRANSFER не работает, и вам нужно установить пользовательские флаги.
Протестировано на Maple Mini. Подключите штифты SPI1 к SPI2 (они установлены как мастер и раб). Он отправляет с помощью SPI.Передача, SPI.dmatransfer (без нулевого sendbuffer), spi.dmasend. Затем он пишет отправленные и полученные байты на Master/Slave SPI в сериал.
Наблюдения: связь, пока DMASEND не работает нормально. чем поврежден.
Если DMASEND прокомментируется, но используется Dmatransfer, Whying работает нормально (почти...).
Фактически внедрение DMA IRQ (с низким приоритетом!!! иначе Spi salve забивается), похоже, решает проблему. Но тогда HAL_DMA_POLLFORTRANSFER не работает, и вам нужно установить пользовательские флаги.
victor_pv
Солнце 07 мая 2017 г. 16:38
victor_pv написал:Даниэфф написал:Добавлен тестовый код в примеры/тестирование/Spiselftest платы
Протестировано на Maple Mini. Подключите штифты SPI1 к SPI2 (они установлены как мастер и раб). Он отправляет с помощью SPI.Передача, SPI.dmatransfer (без нулевого sendbuffer), spi.dmasend. Затем он пишет отправленные и полученные байты на Master/Slave SPI в сериал.
Наблюдения: связь, пока DMASEND не работает нормально. чем поврежден.
Если DMASEND прокомментируется, но используется Dmatransfer, Whying работает нормально (почти...).
Фактически внедрение DMA IRQ (с низким приоритетом!!! иначе Spi salve забивается), похоже, решает проблему. Но тогда HAL_DMA_POLLFORTRANSFER не работает, и вам нужно установить пользовательские флаги.
Протестировано на Maple Mini. Подключите штифты SPI1 к SPI2 (они установлены как мастер и раб). Он отправляет с помощью SPI.Передача, SPI.dmatransfer (без нулевого sendbuffer), spi.dmasend. Затем он пишет отправленные и полученные байты на Master/Slave SPI в сериал.
Наблюдения: связь, пока DMASEND не работает нормально. чем поврежден.
Если DMASEND прокомментируется, но используется Dmatransfer, Whying работает нормально (почти...).
Фактически внедрение DMA IRQ (с низким приоритетом!!! иначе Spi salve забивается), похоже, решает проблему. Но тогда HAL_DMA_POLLFORTRANSFER не работает, и вам нужно установить пользовательские флаги.
Пито
Солнце 07 мая 2017 г., 17:42
Эти цифры довольно низкие.. Также максимальная задержка высока..
При 36 МГц SPI и SDFATEX и DMA вы должны получить ~ 3.5 МБ/с rd/wr..
При 36 МГц SPI и SDFATEX и DMA вы должны получить ~ 3.5 МБ/с rd/wr..
Пито
Солнце 07 мая 2017 г., 21:14
Это с твоим новым SPI.H и SPI.CPP, DMA ON, BLUE F103ZE @72MHZ, 36 МГц SPI, SANDISK 16 ГБ CL10:
File size 5 MB
Buffer size 512 bytes
Starting write test, please wait.
write speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
3576.31,7794,139,141
3566.11,8057,139,141
3563.56,8054,139,141
Starting read test, please wait.
read speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
3162.35,930,159,160
3164.35,903,159,160
3162.35,903,159,160
Donevictor_pv
Солнце 07 мая 2017 г. 9:17 вечера
Пито написал:Это с твоим новым SPI.H и SPI.CPP (Blue F103ZE @72MHZ, 36 МГц SPI, SANDISK CL10):
File size 5 MB
Buffer size 512 bytes
Starting write test, please wait.
write speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
3576.31,7794,139,141
3566.11,8057,139,141
3563.56,8054,139,141
Starting read test, please wait.
read speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
3162.35,930,159,160
3164.35,903,159,160
3162.35,903,159,160
DoneПито
Солнце 07 мая 2017 г., 21:21
Итак, текущий статус:
1. F1 DMA ON - ошибка в F1 DMA найдена и исправлена,
2. F1 Нет DMA - нуждается в отладке/исправлении Даниэля?
3. F4 DMA в порядке (?),
4. F4 Нет DMA - нуждается в отладении/исправлении Даниэля?
Это правильно?
1. F1 DMA ON - ошибка в F1 DMA найдена и исправлена,
2. F1 Нет DMA - нуждается в отладке/исправлении Даниэля?
3. F4 DMA в порядке (?),
4. F4 Нет DMA - нуждается в отладении/исправлении Даниэля?
Это правильно?
victor_pv
Солнце 07 мая 2017 г. 22:02
Пито написал:Итак, текущий статус:
1. F1 DMA ON - ошибка в F1 DMA найдена и исправлена,
2. F1 Нет DMA - нуждается в отладке/исправлении Даниэля?
3. F4 DMA в порядке (?),
4. F4 Нет DMA - нуждается в отладении/исправлении Даниэля?
Это правильно?
1. F1 DMA ON - ошибка в F1 DMA найдена и исправлена,
2. F1 Нет DMA - нуждается в отладке/исправлении Даниэля?
3. F4 DMA в порядке (?),
4. F4 Нет DMA - нуждается в отладении/исправлении Даниэля?
Это правильно?
Даниэфф
Пн, 8 мая 2017 г. 5:05 утра
victor_pv написал:victor_pv написал:
ОБНОВЛЯТЬ:
Похоже, что я наконец люблю проблему. DMA CH .Регистр CCR не принимал значение, потому что канал DMA все еще был включен.
Я думал, что канал сам по себе будет отключенным состоянием, когда трансфер будет завершена, но это не так, и, насколько он включен, CCR не будет изменена в бит MINC. Если я сначала очистите бит CCREN в CCR, то это примет изменения.Не уверен, что работает ли он в F4, потому что HAL позаботится о отключении канала при вызове DMA_INIT, или потому что периферийное устройство вносит изменения, даже если включен, придется проверить больше об этом.
Каждая другая серия, которую я проверил, имеет эти 2 строки в HAL_DMA_INIT, чтобы отключить канал, прежде чем вносить изменения в CCR, кроме F1 HAL:
Похоже, что я наконец люблю проблему. DMA CH .Регистр CCR не принимал значение, потому что канал DMA все еще был включен.
Я думал, что канал сам по себе будет отключенным состоянием, когда трансфер будет завершена, но это не так, и, насколько он включен, CCR не будет изменена в бит MINC. Если я сначала очистите бит CCREN в CCR, то это примет изменения.Не уверен, что работает ли он в F4, потому что HAL позаботится о отключении канала при вызове DMA_INIT, или потому что периферийное устройство вносит изменения, даже если включен, придется проверить больше об этом.
Каждая другая серия, которую я проверил, имеет эти 2 строки в HAL_DMA_INIT, чтобы отключить канал, прежде чем вносить изменения в CCR, кроме F1 HAL:
/* Disable the peripheral */
__HAL_DMA_DISABLE(hdma);Пито
Пн, 8 мая 2017 г. 9:49
При компиляции для F407 я получаю
C:\Users\pito\MyCode\Arduino\hardware\Arduino_STM32SerBuff\STM32DE\libraries\SPI\src\SPI.cpp:234:25: error: 'struct DMA_Stream_TypeDef' has no member named 'CCR'
hdma_spi_tx.Instance->CCR &= ~DMA_CCR_EN;victor_pv
Пн, 8 мая 2017 г. 13:29
Пито написал:При компиляции для F407 я получаю
C:\Users\pito\MyCode\Arduino\hardware\Arduino_STM32SerBuff\STM32DE\libraries\SPI\src\SPI.cpp:234:25: error: 'struct DMA_Stream_TypeDef' has no member named 'CCR'
hdma_spi_tx.Instance->CCR &= ~DMA_CCR_EN;Пито
Пн, 8 мая 2017 г. 15:08
Я прокомментировал материал и собрал для F4, попробовал на 42 МГц, но мой Samsung отказался сотрудничать. Может быть, карта мертва после всех экспериментов.. Вы сделали какие -либо изменения с частью F4, которые могут повлиять на максимальную скорость?
Я еще не пробовал с f1 no dma, я должен покупать новые карты завтра
Я еще не пробовал с f1 no dma, я должен покупать новые карты завтра
victor_pv
Пн, 8 мая 2017 г., 17:26
Пито написал:Я прокомментировал материал и собрал для F4, попробовал на 42 МГц, но мой Samsung отказался сотрудничать. Может быть, карта мертва после всех экспериментов.. Вы сделали какие -либо изменения с частью F4, которые могут повлиять на максимальную скорость?
Я еще не пробовал с f1 no dma, я должен покупать новые карты завтра
Я еще не пробовал с f1 no dma, я должен покупать новые карты завтра
victor_pv
Вторник 09 мая 2017 г. 4:13
Я проводил некоторые тесты по сравнению с Libmaple, и 512bytes Buffer и 16 КБ буфер. Скорости очень похожи.
При температуре 16 КБ буфера Libmaple, кажется, имеет небольшое преимущество в чтениях, и это ядро, похоже, имеет его в записи, но ничего действительно значимого.
Также использование вспышки и оперативной памяти очень похожа, с меньшей вспышкой, используемой в Libmaple и меньшей оперативной памяти, используемой в этом ядре.
Это все с той же SD -картой класса 6.
Использование памяти:
При температуре 16 КБ буфера Libmaple, кажется, имеет небольшое преимущество в чтениях, и это ядро, похоже, имеет его в записи, но ничего действительно значимого.
Также использование вспышки и оперативной памяти очень похожа, с меньшей вспышкой, используемой в Libmaple и меньшей оперативной памяти, используемой в этом ядре.
Это все с той же SD -картой класса 6.
Использование памяти:
libmaple:
section size addr
.text 28048 134217728
.ARM.exidx 8 134245776
.data 2632 536870912
.rodata 3056 134248416
.bss 18952 536873544
Стивестронг
Вторник 09 мая 2017 г. 5:12 утра
Виктор, я предполагаю, что этот тест был проведен для F4, верно? В противном случае барана (.данные и .BSS) преодолел предел 20K чипа F1.
И вы использовали «стандартный» SDFAT LIB, а не SDFATБЫВШИЙ, верно? Можете ли вы также проверить с бывшей версией?
Кстати, соотношение флэш/ОЗУ для Libmaple F1/F4 может быть улучшено, если вы поместите PIN_MAP в Flash, как я сделал это в своей черной ветке F4.
И вы использовали «стандартный» SDFAT LIB, а не SDFATБЫВШИЙ, верно? Можете ли вы также проверить с бывшей версией?
Кстати, соотношение флэш/ОЗУ для Libmaple F1/F4 может быть улучшено, если вы поместите PIN_MAP в Flash, как я сделал это в своей черной ветке F4.
AG123
Вторник 09 мая 2017 г. 7:47 утра
Пито написал:Я прокомментировал материал и собрал для F4, попробовал на 42 МГц, но мой Samsung отказался сотрудничать. Может быть, карта мертва после всех экспериментов.. Вы сделали какие -либо изменения с частью F4, которые могут повлиять на максимальную скорость?
Я еще не пробовал с f1 no dma, я должен покупать новые карты завтра
Я еще не пробовал с f1 no dma, я должен покупать новые карты завтра
Пито
Вторник 09 мая 2017 г. 8:23 утра
Рекомендуется форматировать SDCARD с «форматиром SD -карты» -
https: // www.SDCARD.org/загрузки/formatter_4/
Вместо этого форматировать их с помощью форматеров «Стандартная ОС»..
https: // www.SDCARD.org/загрузки/formatter_4/
Вместо этого форматировать их с помощью форматеров «Стандартная ОС»..
AG123
Вторник 09 мая 2017 г. 9:05 утра
ОТ: Строго говоря, если мы представляем SD -карту в качестве USB -массового хранилища для хоста, эта приличная форма SD -карта S/W может справиться с ней, к сожалению, это будет еще один проект, следовательно, самый быстрый способ на данный момент на данный момент просто получить 1 из этих ключей & запустить S/W
& Для авантюрных может быть возможно скорбят его в Linux
https: // форум.XDA-разработчики.com/showth ... п?T = 502095
Некоторые другие забавные вещи о SD -карте, SD -карты - MCUS
https: // www.Bunniestudios.com/blog/?P = 3554 Суть заключается в том, что механизм загрузки и обновления прошивки является практически обязательным, особенно для сторонних контроллеров. Конечные пользователи редко подвергаются воздействию этого процесса, поскольку все это происходит на фабрике, но это не’t не сделайте механизм менее реальным. В моих исследованиях на рынках электроники в Китае я’Видел, что хранители магазинов сжигают прошивку на картах, которые “расширять” Емкость карты - другими словами, они загружают прошивку, которая сообщает, что емкость карты намного больше, чем фактическое доступное хранилище. Тот факт, что это возможно в точке продажи, означает, что, скорее всего, механизм обновления не защищен.
В нашем выступлении по адресу 30C3 мы сообщаем о наших выводах, изучающих конкретный бренд микроконтроллера, а именно, Appotech и его предложения AX211 и AX215. Мы обнаруживаем просто “поступить” последовательность, передаваемая по командам, задержанным производителем (а именно, cmd63, за которым следует ‘А’,’П’,’П’,’О’) Это бросает контроллер в режим загрузки прошивки. На этом этапе карта примет следующие 512 байтов и запустить ее в качестве кода. http: // s2.Q4CDN.com/000096926/files/doc ... Энтер.PDF 11.3. CSD Регистр
Специфичный для карты данные предоставляет информацию о доступе к содержимому карт.Формат данных, тип коррекции ошибок, максимальное время доступа к данным, можно ли использовать регистр DSR и т. Д.
C_size
Это поле расширено до 22 бит и может указывать до 2 т байта (оно такое же, как максимальное пространство памяти, указанное 32-разрядным блок-адресом.)
Этот параметр используется для вычисления емкости области пользовательских данных на карте памяти SD (не включающая защищенную область). Емкость области пользовательских данных рассчитывается из C_SIZE следующим образом емкость памяти = (C_SIZE+1) * 512K BYTE. В качестве максимальной емкости спецификации физического слоя версии 2.00 составляет 32 ГБ, верхние 6 бит этого поля должны быть установлены на 0. C_SIZE, кажется, подразумевает, что супер секретная «защищенная зона» - это * скрытое разделение * I.эн. Не видно даже с помощью обычного доступа к оборудованию регистрации.
Если это правда, мы могли бы просто просто форматировать * эту карту (с любыми инструментами) и попробуйте еще раз, так как она не затронет эту «защищенную область» в любом случае
Не форматируйте SD -карты с утилитами ОС - на форуме Arduino:
https: // форум.Ардуино.CC/INDEX.PHP?Тема = 228201.0
& Для авантюрных может быть возможно скорбят его в Linux
https: // форум.XDA-разработчики.com/showth ... п?T = 502095
Некоторые другие забавные вещи о SD -карте, SD -карты - MCUS
https: // www.Bunniestudios.com/blog/?P = 3554 Суть заключается в том, что механизм загрузки и обновления прошивки является практически обязательным, особенно для сторонних контроллеров. Конечные пользователи редко подвергаются воздействию этого процесса, поскольку все это происходит на фабрике, но это не’t не сделайте механизм менее реальным. В моих исследованиях на рынках электроники в Китае я’Видел, что хранители магазинов сжигают прошивку на картах, которые “расширять” Емкость карты - другими словами, они загружают прошивку, которая сообщает, что емкость карты намного больше, чем фактическое доступное хранилище. Тот факт, что это возможно в точке продажи, означает, что, скорее всего, механизм обновления не защищен.
В нашем выступлении по адресу 30C3 мы сообщаем о наших выводах, изучающих конкретный бренд микроконтроллера, а именно, Appotech и его предложения AX211 и AX215. Мы обнаруживаем просто “поступить” последовательность, передаваемая по командам, задержанным производителем (а именно, cmd63, за которым следует ‘А’,’П’,’П’,’О’) Это бросает контроллер в режим загрузки прошивки. На этом этапе карта примет следующие 512 байтов и запустить ее в качестве кода. http: // s2.Q4CDN.com/000096926/files/doc ... Энтер.PDF 11.3. CSD Регистр
Специфичный для карты данные предоставляет информацию о доступе к содержимому карт.Формат данных, тип коррекции ошибок, максимальное время доступа к данным, можно ли использовать регистр DSR и т. Д.
C_size
Это поле расширено до 22 бит и может указывать до 2 т байта (оно такое же, как максимальное пространство памяти, указанное 32-разрядным блок-адресом.)
Этот параметр используется для вычисления емкости области пользовательских данных на карте памяти SD (не включающая защищенную область). Емкость области пользовательских данных рассчитывается из C_SIZE следующим образом емкость памяти = (C_SIZE+1) * 512K BYTE. В качестве максимальной емкости спецификации физического слоя версии 2.00 составляет 32 ГБ, верхние 6 бит этого поля должны быть установлены на 0. C_SIZE, кажется, подразумевает, что супер секретная «защищенная зона» - это * скрытое разделение * I.эн. Не видно даже с помощью обычного доступа к оборудованию регистрации.
Если это правда, мы могли бы просто просто форматировать * эту карту (с любыми инструментами) и попробуйте еще раз, так как она не затронет эту «защищенную область» в любом случае
Не форматируйте SD -карты с утилитами ОС - на форуме Arduino:
https: // форум.Ардуино.CC/INDEX.PHP?Тема = 228201.0
michael_l
Вторник 09 мая 2017 г. 10:32 утра
Можно ли создать тестовую программу для одной платы, используя SPI1 (MASTER) и SPI2 (SLAVE), чтобы проверить функциональность SPI и DMA. Тестовые примеры могут быть просто отправлять байты и читать их из SPI2.
Даниэфф
Вторник 09 мая 2017 г. 10:45
michael_l написал:Можно ли создать тестовую программу для одной платы, используя SPI1 (MASTER) и SPI2 (SLAVE), чтобы проверить функциональность SPI и DMA. Тестовые примеры могут быть просто отправлять байты и читать их из SPI2.
AG123
Вторник 09 мая 2017 г. 10:49
Я не слишком уверен, что довольно «веселый» способ проверить его, чтобы подключить мисо с Моси, если я правильно понимаю SPI, SPI.Передача (0xaa) будет отражена в качестве возврата, это, вероятно, не очень хороший тест
victor_pv
Вторник 09 мая 2017 12:38
Стивестронг написал:Виктор, я предполагаю, что этот тест был проведен для F4, верно? В противном случае барана (.данные и .BSS) преодолел предел 20K чипа F1.
И вы использовали «стандартный» SDFAT LIB, а не SDFATБЫВШИЙ, верно? Можете ли вы также проверить с бывшей версией?
Кстати, соотношение флэш/ОЗУ для Libmaple F1/F4 может быть улучшено, если вы поместите PIN_MAP в Flash, как я сделал это в своей черной ветке F4.
И вы использовали «стандартный» SDFAT LIB, а не SDFATБЫВШИЙ, верно? Можете ли вы также проверить с бывшей версией?
Кстати, соотношение флэш/ОЗУ для Libmaple F1/F4 может быть улучшено, если вы поместите PIN_MAP в Flash, как я сделал это в своей черной ветке F4.
Стивестронг
Вторник 09 мая 2017 12:43
victor_pv написал:На ядре Libmaple для F1 мы уже размещаем PIN_MAP во Flash.
michael_l
Вторник 09 мая 2017 12:45
Даниэфф написал:michael_l написал:Можно ли создать тестовую программу для одной платы, используя SPI1 (MASTER) и SPI2 (SLAVE), чтобы проверить функциональность SPI и DMA. Тестовые примеры могут быть просто отправлять байты и читать их из SPI2.
victor_pv
Вторник 09 мая 2017 г. 13:09
Стивестронг написал:victor_pv написал:На ядре Libmaple для F1 мы уже размещаем PIN_MAP во Flash.
Стивестронг
Вторник 09 мая 2017 г. 14:36
Виктор, я не могу идентифицировать соответствующий коммит, чтобы поместить PIN_MAP в Flash из списка для главной ветви: https: // github.com/rogerclarkmelbourne/ ... его/Мастер
Вы, скорее всего, используете либо "PIN_MAP_IN_FLASH", либо ветвь "PIN_MAP_IN_FLASH_TAKE_2".
Да, как вы, наверное, заметили, я не отказываюсь от ядра Libmaple, моя «первая любовь»
Я уже адаптировал каналы DMA от F1 к потокам для F4, это было не очень сложно, 2 часа работы.
DMA еще не работает с SPI, я должен отлаживать его. Но я уверен, что это сработает.
Тем временем я оптимизирую рутину многократного (не-DMA) для SPI, чтобы получить (в основном) непрерывные часы при чтении байтов, аналогично процедуре записи. У меня была аналогичная попытка пару месяцев назад, это не работало, но теперь я нашел способ заставить его правильно работать.
Производительность WR версии Non-DMA, что я проверил, кажется, очень близко к версии DMA Generic Core @21 МГц, согласно измерениям Пито.
Вы, скорее всего, используете либо "PIN_MAP_IN_FLASH", либо ветвь "PIN_MAP_IN_FLASH_TAKE_2".
Да, как вы, наверное, заметили, я не отказываюсь от ядра Libmaple, моя «первая любовь»
Я уже адаптировал каналы DMA от F1 к потокам для F4, это было не очень сложно, 2 часа работы.
DMA еще не работает с SPI, я должен отлаживать его. Но я уверен, что это сработает.
Тем временем я оптимизирую рутину многократного (не-DMA) для SPI, чтобы получить (в основном) непрерывные часы при чтении байтов, аналогично процедуре записи. У меня была аналогичная попытка пару месяцев назад, это не работало, но теперь я нашел способ заставить его правильно работать.
Производительность WR версии Non-DMA, что я проверил, кажется, очень близко к версии DMA Generic Core @21 МГц, согласно измерениям Пито.
victor_pv
Вторник 09 мая 2017 г. 16:58
Стивестронг написал:Виктор, я не могу идентифицировать соответствующий коммит, чтобы поместить PIN_MAP в Flash из списка для главной ветви: https: // github.com/rogerclarkmelbourne/ ... его/Мастер
Вы, скорее всего, используете либо "PIN_MAP_IN_FLASH", либо ветвь "PIN_MAP_IN_FLASH_TAKE_2".
Да, как вы, наверное, заметили, я не отказываюсь от ядра Libmaple, моя «первая любовь»
Я уже адаптировал каналы DMA от F1 к потокам для F4, это было не очень сложно, 2 часа работы.
DMA еще не работает с SPI, я должен отлаживать его. Но я уверен, что это сработает.
Тем временем я оптимизирую рутину многократного (не-DMA) для SPI, чтобы получить (в основном) непрерывные часы при чтении байтов, аналогично процедуре записи. У меня была аналогичная попытка пару месяцев назад, это не работало, но теперь я нашел способ заставить его правильно работать.
Производительность WR версии Non-DMA, что я проверил, кажется, очень близко к версии DMA Generic Core @21 МГц, согласно измерениям Пито.
Вы, скорее всего, используете либо "PIN_MAP_IN_FLASH", либо ветвь "PIN_MAP_IN_FLASH_TAKE_2".
Да, как вы, наверное, заметили, я не отказываюсь от ядра Libmaple, моя «первая любовь»
Я уже адаптировал каналы DMA от F1 к потокам для F4, это было не очень сложно, 2 часа работы.
DMA еще не работает с SPI, я должен отлаживать его. Но я уверен, что это сработает.
Тем временем я оптимизирую рутину многократного (не-DMA) для SPI, чтобы получить (в основном) непрерывные часы при чтении байтов, аналогично процедуре записи. У меня была аналогичная попытка пару месяцев назад, это не работало, но теперь я нашел способ заставить его правильно работать.
Производительность WR версии Non-DMA, что я проверил, кажется, очень близко к версии DMA Generic Core @21 МГц, согласно измерениям Пито.
Стивестронг
Вторник 09 мая 2017 г., 17:24
Виктор, ваш анализ был правильным, по крайней мере, идентичен моим.
Наиболее важной частью является чтение данных RX (N) до написания TX (N+1).
И решение действительно заключается в том, чтобы отключить прерывания между письменным байтом (n) и байтом для чтения (N-1). Тогда прерывания снова могут быть включены.
Максимальное зарезервированное время составляет до 8 периодов SPI.
Вот как это выглядит в код C:
Наиболее важной частью является чтение данных RX (N) до написания TX (N+1).
И решение действительно заключается в том, чтобы отключить прерывания между письменным байтом (n) и байтом для чтения (N-1). Тогда прерывания снова могут быть включены.
Максимальное зарезервированное время составляет до 8 периодов SPI.
Вот как это выглядит в код C:
void SPIClass::read(uint8 *buf, uint32 len)
{
if ( len == 0 ) return;
spi_rx_reg(_currentSetting->spi_d); // clear the RX buffer in case a byte is waiting on it.
spi_reg_map * regs = _currentSetting->spi_d->regs;
// start sequence: write byte 0
regs->DR = 0x00FF; // write the first byte
// main loop
while ( (--len) ) {
while( !(regs->SR & SPI_SR_TXE) ); // wait for TXE flag
noInterrupts(); // go atomic level - avoid interrupts to surely get the previously received data
regs->DR = 0x00FF; // write the next data item to be transmitted into the SPI_DR register. This clears the TXE flag.
while ( !(regs->SR & SPI_SR_RXNE) ); // wait till data is available in the DR register
*buf++ = (uint8)(regs->DR); // read and store the received byte. This clears the RXNE flag.
interrupts(); // let systick do its job
}
// read remaining last byte
while ( !(regs->SR & SPI_SR_RXNE) ); // wait till data is available in the Rx register
*buf = (uint8)(regs->DR); // read and store the last received byte
}victor_pv
Вторник 09 мая 2017 г., 17:33
Стивестронг написал:Виктор, я не могу идентифицировать соответствующий коммит, чтобы поместить PIN_MAP в Flash из списка для главной ветви: https: // github.com/rogerclarkmelbourne/ ... его/Мастер
Вы, скорее всего, используете либо "PIN_MAP_IN_FLASH", либо ветвь "PIN_MAP_IN_FLASH_TAKE_2".
Вы, скорее всего, используете либо "PIN_MAP_IN_FLASH", либо ветвь "PIN_MAP_IN_FLASH_TAKE_2".
Стивестронг
Вторник 09 мая 2017 г., 17:38
Да, действительно, вы правы, теперь я понимаю, что вместо этого проверяю старый файл карты F4.
В любом случае, я тоже добавил ту же функцию в мою черную ветвь F4.
В любом случае, я тоже добавил ту же функцию в мою черную ветвь F4.
victor_pv
Вторник 09 мая 2017 г., 17:50
Стив, великие умы думают одинаково 
Но я подозреваю, что этого может быть недостаточно.
Что произойдет, если между этой строкой запускается прерывание
регс->Dr = 0x00ff; // Написать первый балл
и
noEverseRrupts (); // go по атомному уровню - избегайте прерываний, чтобы наверняка получить ранее полученные данные
ISR будет вызван, подсчитайте 13 циклов мин, первый байт полностью сдвинут, вход байта переходит к доктору. Затем ISR возвращается, прерывания отключено, вы пишете новый байт DR, который начинает быстро перемещаться с тех пор, как предыдущий завершен (я думаю, что для перехода от DR FIFO требуется 1 цикл в регистр SPI Shift), вам нужно выполнить Все это до того, как он завершит, смещается с этим вторым байтом:
пока ( !(Регс->Старший & Spi_sr_rxne)); // подождать, пока данные не доступны в реестре DR
*buf ++ = (uint8) (regs->DR);
Если эти 2 строки не могут завершить за 8 циклов, мы потеряли байт. (Но не скорее будет ближе к 16 циклам максимум, так как SPI работает на 36 МГц макс?).
Если это 16 циклов, то может быть достаточно, если я ошибаюсь, и это 8, то вам может потребоваться проверить сгенерированный код, чтобы убедиться, что он не сдает слишком много инструкций, и это может быть даже вне нашего контроля Если люди меняют флаги оптимизации...
Кстати, я говорю о циклах процессоров, а не о циклах SPI.
РЕДАКТИРОВАТЬ: Я вижу, вы говорили 8 циклов SPI, поэтому мы говорим в то же время на максимальной скорости. 8 SPI или 16 циклов процессора в F1. С этим я не вижу проблем, если компилятор не сделает что -то сумасшедшее с этими двумя линиями.
F1 должен извлечь выгоду из тех же изменений, что был ваш тест выше в F1 или F4?
В трансферной функции вы сможете сделать то же самое, чтобы оптимизировать скорость, если мы отправляем более 1 байта. Вы тестировали оптимизацию этого?
Но я подозреваю, что этого может быть недостаточно.
Что произойдет, если между этой строкой запускается прерывание
регс->Dr = 0x00ff; // Написать первый балл
и
noEverseRrupts (); // go по атомному уровню - избегайте прерываний, чтобы наверняка получить ранее полученные данные
ISR будет вызван, подсчитайте 13 циклов мин, первый байт полностью сдвинут, вход байта переходит к доктору. Затем ISR возвращается, прерывания отключено, вы пишете новый байт DR, который начинает быстро перемещаться с тех пор, как предыдущий завершен (я думаю, что для перехода от DR FIFO требуется 1 цикл в регистр SPI Shift), вам нужно выполнить Все это до того, как он завершит, смещается с этим вторым байтом:
пока ( !(Регс->Старший & Spi_sr_rxne)); // подождать, пока данные не доступны в реестре DR
*buf ++ = (uint8) (regs->DR);
Если эти 2 строки не могут завершить за 8 циклов, мы потеряли байт. (Но не скорее будет ближе к 16 циклам максимум, так как SPI работает на 36 МГц макс?).
Если это 16 циклов, то может быть достаточно, если я ошибаюсь, и это 8, то вам может потребоваться проверить сгенерированный код, чтобы убедиться, что он не сдает слишком много инструкций, и это может быть даже вне нашего контроля Если люди меняют флаги оптимизации...
Кстати, я говорю о циклах процессоров, а не о циклах SPI.
РЕДАКТИРОВАТЬ: Я вижу, вы говорили 8 циклов SPI, поэтому мы говорим в то же время на максимальной скорости. 8 SPI или 16 циклов процессора в F1. С этим я не вижу проблем, если компилятор не сделает что -то сумасшедшее с этими двумя линиями.
F1 должен извлечь выгоду из тех же изменений, что был ваш тест выше в F1 или F4?
В трансферной функции вы сможете сделать то же самое, чтобы оптимизировать скорость, если мы отправляем более 1 байта. Вы тестировали оптимизацию этого?
Стивестронг
Вторник 09 мая 2017 г. 18:02
Виктор, у меня была такая же беспокойство.
Но здесь я предположил, что процессор способен выполнить эти пару инструкций, так как часы процессора всегда равен кратным часами SPI.
Я исследую количество необходимых инструкций с отладчиком, скоро вернусь к этому.
Но здесь я предположил, что процессор способен выполнить эти пару инструкций, так как часы процессора всегда равен кратным часами SPI.
Я исследую количество необходимых инструкций с отладчиком, скоро вернусь к этому.
victor_pv
Вторник 09 мая 2017 г. 18:13
Стивестронг написал:Виктор, у меня была такая же беспокойство.
Но здесь я предположил, что процессор способен выполнить эти пару инструкций, так как часы процессора всегда равен кратным часами SPI.
Я исследую количество необходимых инструкций с отладчиком, скоро вернусь к этому.
Но здесь я предположил, что процессор способен выполнить эти пару инструкций, так как часы процессора всегда равен кратным часами SPI.
Я исследую количество необходимых инструкций с отладчиком, скоро вернусь к этому.
Пито
Вторник 09 мая 2017 г. 18:16
Вы также можете выполнить 16 -битные передачи с помощью SPI (не уверен с 32 -битным, PIC32MX может сделать).
Кстати, лучший чек на SPI с SDFAT будет под Freertos
Кстати, лучший чек на SPI с SDFAT будет под Freertos
Стивестронг
Вторник 09 мая 2017 г. 18:52
Это код сборки новой функции чтения блока.
SPIClass::read(unsigned char*, unsigned int):
080068be: 0x000030b5 push {r4, r5, lr}
336 if ( len == 0 ) return;
080068c0: 0x0000f2b1 cbz r2, 0x8006900
337 spi_rx_reg(_currentSetting->spi_d); // clear the RX buffer in case a byte is waiting on it.
080068c2: 0x0000036e ldr r3, [r0, #96] ; 0x60
080068c4: 0x0000db68 ldr r3, [r3, #12]
080068c6: 0x00001b68 ldr r3, [r3, #0]
080068c8: 0x0000d868 ldr r0, [r3, #12]
341 regs->DR = 0x00FF; // write the first byte
080068ca: 0x0000ff20 movs r0, #255 ; 0xff
080068cc: 0x0000d860 str r0, [r3, #12]
080068ce: 0x00008c18 adds r4, r1, r2
080068d0: 0x0000481c adds r0, r1, #1
343 while ( (--len) ) {
080068d2: 0x0000a042 cmp r0, r4
080068d4: 0x00000ed0 beq.n 0x80068f4
344 while( !(regs->SR & SPI_SR_TXE) ); // wait for TXE flag
080068d6: 0x00009d68 ldr r5, [r3, #8]
080068d8: 0x0000ad07 lsls r5, r5, #30
080068da: 0x0000fcd5 bpl.n 0x80068d6
080068dc: 0x000072b6 cpsid i
346 regs->DR = 0x00FF; // write the next data item to be transmitted into the SPI_DR register. This clears the TXE flag.
080068de: 0x0000ff25 movs r5, #255 ; 0xff
080068e0: 0x0000dd60 str r5, [r3, #12]
347 while ( !(regs->SR & SPI_SR_RXNE) ); // wait till data is available in the DR register
080068e2: 0x00009d68 ldr r5, [r3, #8]
080068e4: 0x0000ed07 lsls r5, r5, #31
080068e6: 0x0000fcd5 bpl.n 0x80068e2
348 *buf++ = (uint8)(regs->DR); // read and store the received byte. This clears the RXNE flag.
080068e8: 0x0000dd68 ldr r5, [r3, #12]
080068ea: 0x00f8015c strb.w r5, [r0, #-1]
080068ee: 0x000062b6 cpsie i
080068f0: 0x00000130 adds r0, #1
080068f2: 0x0000eee7 b.n 0x80068d2
080068f4: 0x0000013a subs r2, #1
352 while ( !(regs->SR & SPI_SR_RXNE) ); // wait till data is available in the Rx register
080068f6: 0x00009868 ldr r0, [r3, #8]
080068f8: 0x0000c007 lsls r0, r0, #31
080068fa: 0x0000fcd5 bpl.n 0x80068f6
353 *buf++ = (uint8)(regs->DR); // read and store the received byte
080068fc: 0x0000db68 ldr r3, [r3, #12]
080068fe: 0x00008b54 strb r3, [r1, r2]
08006900: 0x000030bd pop {r4, r5, pc}
victor_pv
Вторник 09 мая 2017 г., 19:48
Стивестронг написал:Это код сборки новой функции чтения блока.
SPIClass::read(unsigned char*, unsigned int):
080068be: 0x000030b5 push {r4, r5, lr}
336 if ( len == 0 ) return;
080068c0: 0x0000f2b1 cbz r2, 0x8006900
337 spi_rx_reg(_currentSetting->spi_d); // clear the RX buffer in case a byte is waiting on it.
080068c2: 0x0000036e ldr r3, [r0, #96] ; 0x60
080068c4: 0x0000db68 ldr r3, [r3, #12]
080068c6: 0x00001b68 ldr r3, [r3, #0]
080068c8: 0x0000d868 ldr r0, [r3, #12]
341 regs->DR = 0x00FF; // write the first byte
080068ca: 0x0000ff20 movs r0, #255 ; 0xff
080068cc: 0x0000d860 str r0, [r3, #12]
080068ce: 0x00008c18 adds r4, r1, r2
080068d0: 0x0000481c adds r0, r1, #1
343 while ( (--len) ) {
080068d2: 0x0000a042 cmp r0, r4
080068d4: 0x00000ed0 beq.n 0x80068f4
344 while( !(regs->SR & SPI_SR_TXE) ); // wait for TXE flag
080068d6: 0x00009d68 ldr r5, [r3, #8]
080068d8: 0x0000ad07 lsls r5, r5, #30
080068da: 0x0000fcd5 bpl.n 0x80068d6
080068dc: 0x000072b6 cpsid i
346 regs->DR = 0x00FF; // write the next data item to be transmitted into the SPI_DR register. This clears the TXE flag.
080068de: 0x0000ff25 movs r5, #255 ; 0xff
080068e0: 0x0000dd60 str r5, [r3, #12]
347 while ( !(regs->SR & SPI_SR_RXNE) ); // wait till data is available in the DR register
080068e2: 0x00009d68 ldr r5, [r3, #8]
080068e4: 0x0000ed07 lsls r5, r5, #31
080068e6: 0x0000fcd5 bpl.n 0x80068e2
348 *buf++ = (uint8)(regs->DR); // read and store the received byte. This clears the RXNE flag.
080068e8: 0x0000dd68 ldr r5, [r3, #12]
080068ea: 0x00f8015c strb.w r5, [r0, #-1]
080068ee: 0x000062b6 cpsie i
080068f0: 0x00000130 adds r0, #1
080068f2: 0x0000eee7 b.n 0x80068d2
080068f4: 0x0000013a subs r2, #1
352 while ( !(regs->SR & SPI_SR_RXNE) ); // wait till data is available in the Rx register
080068f6: 0x00009868 ldr r0, [r3, #8]
080068f8: 0x0000c007 lsls r0, r0, #31
080068fa: 0x0000fcd5 bpl.n 0x80068f6
353 *buf++ = (uint8)(regs->DR); // read and store the received byte
080068fc: 0x0000db68 ldr r3, [r3, #12]
080068fe: 0x00008b54 strb r3, [r1, r2]
08006900: 0x000030bd pop {r4, r5, pc}
AG123
Вторник 09 мая 2017 г. 8:44 вечера
Вау, эти вещи довольно сложны, в то время как я пытаюсь выяснить их на часовых диаграммах в RM, но я выясню 1 маленькую вещь, поскольку прерывания отключены, ожидая следующего входящего байта, как только это прибудет чтение, которое включает прерывания , Проверьте доступность записи, ОК, чтобы написать, отключить прерывания, написать байт, подождать, пока мы снова получаем байты. Самое забавное, казалось, что вряд ли будет шанс, что прерывание произойдет, пока записывает, подождите, читает петля
Я предполагаю, что невозможно иметь торт & Ешьте это, но это показывает, что вмешается с обнаженным металлом, нелегко с большим количеством компромиссов, E.глин. ЦП занят, клавишные, USB -серийные поднусания не будут посещать, пока это не будет сделано
В любом случае 4 МБ (32 Мбит/ с) за секунды отлично подходят для передачи SPI на одном выводе, многозадачные задания все еще могут быть достигнуты на более высоком уровне, давая, скажем, каждые 4 -километровые байты, так что другие задачи имели возможность выполнять, на этих скоростях чтение/ чтение/ Напишите 4K байтов. Возьмите всего 1 мс! Ether Way на F1, он должен был бы дать на 512 байт из -за отсутствия ОЗУ
Мне показалось бы, что для работы без прерывания подавления, протокол выше этого аппаратного слоя SPI должен иметь некоторые механизмы коррекции ошибок, E.глин. Если байт пропускается во время чтения из-за прерывания, контрольная сумма должна поймать так, чтобы мастер/хост мог запросить тот же пакет, который будет переведен , но также не будет легко выяснить эти сложные взаимодействия
Я предполагаю, что невозможно иметь торт & Ешьте это, но это показывает, что вмешается с обнаженным металлом, нелегко с большим количеством компромиссов, E.глин. ЦП занят, клавишные, USB -серийные поднусания не будут посещать, пока это не будет сделано
В любом случае 4 МБ (32 Мбит/ с) за секунды отлично подходят для передачи SPI на одном выводе, многозадачные задания все еще могут быть достигнуты на более высоком уровне, давая, скажем, каждые 4 -километровые байты, так что другие задачи имели возможность выполнять, на этих скоростях чтение/ чтение/ Напишите 4K байтов. Возьмите всего 1 мс! Ether Way на F1, он должен был бы дать на 512 байт из -за отсутствия ОЗУ
Мне показалось бы, что для работы без прерывания подавления, протокол выше этого аппаратного слоя SPI должен иметь некоторые механизмы коррекции ошибок, E.глин. Если байт пропускается во время чтения из-за прерывания, контрольная сумма должна поймать так, чтобы мастер/хост мог запросить тот же пакет, который будет переведен , но также не будет легко выяснить эти сложные взаимодействия
victor_pv
Вторник 09 мая 2017 г. 9:35 вечера
AG123 написал:Вау, эти вещи довольно сложны, в то время как я пытаюсь выяснить их на часовых диаграммах в RM, но я выясню 1 маленькую вещь, поскольку прерывания отключены, ожидая следующего входящего байта, как только это прибудет чтение, которое включает прерывания , Проверьте доступность записи, ОК, чтобы написать, отключить прерывания, написать байт, подождать, пока мы снова получаем байты. Самое забавное, казалось, что вряд ли будет шанс, что прерывание произойдет, пока записывает, подождите, читает петля
Я предполагаю, что невозможно иметь торт & Ешьте это, но это показывает, что вмешается с обнаженным металлом, нелегко с большим количеством компромиссов, E.глин. ЦП занят, клавишные, USB -серийные поднусания не будут посещать, пока это не будет сделано
В любом случае 4 МБ (32 Мбит/ с) за секунды отлично подходят для передачи SPI на одном выводе, многозадачные задания все еще могут быть достигнуты на более высоком уровне, давая, скажем, каждые 4 -километровые байты, так что другие задачи имели возможность выполнять, на этих скоростях чтение/ чтение/ Напишите 4K байтов. Возьмите всего 1 мс! Ether Way на F1, он должен был бы дать на 512 байт из -за отсутствия ОЗУ
Я предполагаю, что невозможно иметь торт & Ешьте это, но это показывает, что вмешается с обнаженным металлом, нелегко с большим количеством компромиссов, E.глин. ЦП занят, клавишные, USB -серийные поднусания не будут посещать, пока это не будет сделано
В любом случае 4 МБ (32 Мбит/ с) за секунды отлично подходят для передачи SPI на одном выводе, многозадачные задания все еще могут быть достигнуты на более высоком уровне, давая, скажем, каждые 4 -километровые байты, так что другие задачи имели возможность выполнять, на этих скоростях чтение/ чтение/ Напишите 4K байтов. Возьмите всего 1 мс! Ether Way на F1, он должен был бы дать на 512 байт из -за отсутствия ОЗУ
victor_pv
Ср 10 мая 2017 г. 2:40
Вау, не могу поверить в ночную разницу при использовании sdfatex!!
Такая же карта класса 6 с 512 буфером получает 3 МБ/с, и использование буфера 16 КБ едва ли улучшает его, так что, похоже, это предел для этой карты.
STM32GENERIERIERE CORE, F103RFT MCU, 72 МГц, DMA, DIV/2, SDFATEX, 512 байт буфер:
Такая же карта класса 6 с 512 буфером получает 3 МБ/с, и использование буфера 16 КБ едва ли улучшает его, так что, похоже, это предел для этой карты.
STM32GENERIERIERE CORE, F103RFT MCU, 72 МГц, DMA, DIV/2, SDFATEX, 512 байт буфер:
FreeStack: 92664
Type is FAT32
Card size: 4.08 GB (GB = 1E9 bytes)
Manufacturer ID: 0X3
OEM ID: SD
Product: SD04G
Version: 8.0
Serial number: 0X5700E101
Manufacturing date: 8/2008
File size 5 MB
Buffer size 512 bytes
Starting write test, please wait.
write speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
3071.06,154124,141,164
3391.91,24856,141,148
3056.04,153749,141,165
Starting read test, please wait.
read speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
3054.17,1200,165,166
3054.17,1201,165,166
3054.17,1202,165,166
Done
Type any character to start
AG123
Ср 10 мая 2017 г., 7:22
Это, вероятно, * намного * быстрее, чем те дешевые USB -читатели карт & Кстати, USB Полная скорость - это всего лишь 12 Мбит / с. В нашем случае на самом SPI мы делаем 24 миль на пса (3 кбит
victor_pv
Ср 10 мая 2017 г. 20:56
После короткого обсуждения здесь со Стивом о том, как оптимизировать цикл переноса, чтобы сохранить FLE -SPI без потери данных, я пошел проверить, насколько оптимальным является HAL.
Помимо кучи накладных расходов, запуская передачу, остальная часть петли точно такая же, отправьте 2 байта, затем прочитайте и отправьте 1 за один, и прочитайте последний.
Но с 1 основным отличием. Он не отключает прерывания в любое время! По крайней мере, не в Hals F1 и F4.
Я думаю, что это может объяснить, что коррупция получала, когда проходила тесты без DMA. Поскольку прерывания включены и продолжаются для Systick, USB...
Помимо кучи накладных расходов, запуская передачу, остальная часть петли точно такая же, отправьте 2 байта, затем прочитайте и отправьте 1 за один, и прочитайте последний.
Но с 1 основным отличием. Он не отключает прерывания в любое время! По крайней мере, не в Hals F1 и F4.
Я думаю, что это может объяснить, что коррупция получала, когда проходила тесты без DMA. Поскольку прерывания включены и продолжаются для Systick, USB...
Стивестронг
Ср 10 мая 2017 г., 21:47
Я также думаю, что прерывание отключения/включения последовательности имеет решающее значение, в противном случае данные могут быть повреждены.
РЕДАКТИРОВАТЬ
Для сравнения, скамейка Libmaple Core SD на синей таблетках для моей карты Sandisk Ultra Cl10 (красный/серый), F103 @ 72mhz, SPI1 @ 36 МГц, с DMA:
РЕДАКТИРОВАТЬ
Для сравнения, скамейка Libmaple Core SD на синей таблетках для моей карты Sandisk Ultra Cl10 (красный/серый), F103 @ 72mhz, SPI1 @ 36 МГц, с DMA:
File size 5 MB
Buffer size 512 bytes
Starting write test, please wait.
write speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
3700.73,9752,131,136
3703.47,16335,131,136
Starting read test, please wait.
read speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
3382.73,989,149,150
3385.02,847,149,150
Даниэфф
Чт 11 мая 2017 г., 6:35 утра
Я смотрел на API SPI.
Вот компиляция реализаций в различных ядрах: https: // Gist.GitHub.com/danieleff/64e51 ... 6AB1167AD7
(Текущее обсуждение форумов Arduino Dev: https: // группы.Google.com/a/bcmi-labs.в ... 12i7sb_elk )
Libmaple выглядит просто... странный?
Вот компиляция реализаций в различных ядрах: https: // Gist.GitHub.com/danieleff/64e51 ... 6AB1167AD7
(Текущее обсуждение форумов Arduino Dev: https: // группы.Google.com/a/bcmi-labs.в ... 12i7sb_elk )
Libmaple выглядит просто... странный?
victor_pv
Чт 11 мая 2017 г. 13:35
Даниэфф написал:Я смотрел на API SPI.
Вот компиляция реализаций в различных ядрах: https: // Gist.GitHub.com/danieleff/64e51 ... 6AB1167AD7
(Текущее обсуждение форумов Arduino Dev: https: // группы.Google.com/a/bcmi-labs.в ... 12i7sb_elk )
Libmaple выглядит просто... странный?
Вот компиляция реализаций в различных ядрах: https: // Gist.GitHub.com/danieleff/64e51 ... 6AB1167AD7
(Текущее обсуждение форумов Arduino Dev: https: // группы.Google.com/a/bcmi-labs.в ... 12i7sb_elk )
Libmaple выглядит просто... странный?
AG123
Чт 11 мая 2017 г. 14:19
о, я невежественно просто использую SPI.Передача (0xAA) и SPI.Transfer16 (0xaaaa), они, казалось, просто работали «из коробки»
не понял, что есть довольно много SPI «История» с различными интерфейсами
не понял, что есть довольно много SPI «История» с различными интерфейсами
Пито
Сб 13 мая 2017 г. 10:17
С последним SPI Victor's STM32GENERIER, я не могу получить более 800 КБ/с с любыми настройками скорости на скамейке с F407..
victor_pv
Сб 13 мая 2017 г. 14:26
Пито написал:С последним SPI Victor's STM32GENERIER, я не могу получить более 800 КБ/с с любыми настройками скорости на скамейке с F407..
Пито
Сб 13 мая 2017 г. 14:39
Да, я сделал все возможное сегодня с F407, но макс был ~ 800 КБ/с для скоростей SPI с 10-51 на скамейке, с 3 картами, SPI, SDFATEX, DMA 
Я дважды проверяю с той же SPI (последний) с F1 сейчас..
Blue F103Zet, New Samsung Evo 16 ГБ CL10, 36 МГц SPI Speed, Sdfatex, DMA:
Я дважды проверяю с той же SPI (последний) с F1 сейчас..
Blue F103Zet, New Samsung Evo 16 ГБ CL10, 36 МГц SPI Speed, Sdfatex, DMA:
File size 5 MB
Buffer size 512 bytes
Starting write test, please wait.
write speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
3431.49,16295,140,146
3472.00,8603,140,145
3438.57,20800,140,147
Starting read test, please wait.
read speed and latency
speed,max,min,avg
KB/Sec,usec,usec,usec
3176.42,1878,158,159
3180.46,1414,158,159
3180.46,1417,158,159AG123
Сб 13 мая 2017 г. 15:39
Может быть, агрессивный * no_Enterrupts () * предотвратил коррупцию данных, но оставляет большую очередь от SD FAT, ожидая, чтобы «выполнить свою работу»
victor_pv
Сб 13 мая 2017 г. 18:29
Мы не отключаем прерывания в версии STM322ERIER, только на ядрах Libmaple, и только Стив реализовал ее до сих пор, пока еще не в ядре, так что это не будет связано.
Я несколько раз поймал его с отладчиком, ожидающим ожидания TXE на съемочную площадку, и останусь на 0. У меня до сих пор нет объяснения этого. И я видел это в F1 только настолько, насколько я помню.
До тех пор, пока включено периферийное устройство SPI, после нескольких циклов TXE должно стать 1, когда текущие данные полностью сдвинуты, но несколько раз это не происходит. Это может быть связано с тем, что отладчик подключился и застрял вокруг данных и регистров, не уверен, но просто не может понять, почему это произойдет.
Кроме этого, 20 -сантиметровые провода могут быть только на пределе его работы или нет, вы получаете немного больше шума в линии при 42 МГц, а порт SPI или SDCARD пропускает края...
Я сделал несколько косметических исправлений, но ничего серьезного, и просто подтолкнул эти обновления в мою репо. Я не отправил новый пиар в Даниэль, пока мы не подтвердим, что сама библиотека будет надежна. Я должен подключить гнездо SDCARD на плату F4 и провести несколько тестов.
Я думаю, было бы хорошо проверить библиотеку с дисплеями, так как они сделают очень очевидным, если что -то повреждено на экране. Вероятно, больше, чтобы испытать скамейку, так как я думаю, что она не проверяет каждый байт на чтениях, но только последние 2 из каждого блока.
Я несколько раз поймал его с отладчиком, ожидающим ожидания TXE на съемочную площадку, и останусь на 0. У меня до сих пор нет объяснения этого. И я видел это в F1 только настолько, насколько я помню.
До тех пор, пока включено периферийное устройство SPI, после нескольких циклов TXE должно стать 1, когда текущие данные полностью сдвинуты, но несколько раз это не происходит. Это может быть связано с тем, что отладчик подключился и застрял вокруг данных и регистров, не уверен, но просто не может понять, почему это произойдет.
Кроме этого, 20 -сантиметровые провода могут быть только на пределе его работы или нет, вы получаете немного больше шума в линии при 42 МГц, а порт SPI или SDCARD пропускает края...
Я сделал несколько косметических исправлений, но ничего серьезного, и просто подтолкнул эти обновления в мою репо. Я не отправил новый пиар в Даниэль, пока мы не подтвердим, что сама библиотека будет надежна. Я должен подключить гнездо SDCARD на плату F4 и провести несколько тестов.
Я думаю, было бы хорошо проверить библиотеку с дисплеями, так как они сделают очень очевидным, если что -то повреждено на экране. Вероятно, больше, чтобы испытать скамейку, так как я думаю, что она не проверяет каждый байт на чтениях, но только последние 2 из каждого блока.
Пито
Сб 13 мая 2017 г., 19:14
У меня есть Jlink, постоянно подключенная к F407 - я делаю вспышку через Jlink.. Может, это как -то вмешалось сегодня утром.. Я тоже должен сократить провода..
В любом случае, нам нужно больше тестеров для SPI и SDIO, чтобы участвовать
В любом случае, нам нужно больше тестеров для SPI и SDIO, чтобы участвовать
Даниэфф
Солнце 14 мая 2017 г., 4:24
victor_pv написал:Даниэфф написал:Я смотрел на API SPI.
Вот компиляция реализаций в различных ядрах: https: // Gist.GitHub.com/danieleff/64e51 ... 6AB1167AD7
(Текущее обсуждение форумов Arduino Dev: https: // группы.Google.com/a/bcmi-labs.в ... 12i7sb_elk )
Libmaple выглядит просто... странный?
Вот компиляция реализаций в различных ядрах: https: // Gist.GitHub.com/danieleff/64e51 ... 6AB1167AD7
(Текущее обсуждение форумов Arduino Dev: https: // группы.Google.com/a/bcmi-labs.в ... 12i7sb_elk )
Libmaple выглядит просто... странный?
Стивестронг
Солнце 14 мая 2017 г. 8:44
Даниэфф написал:Вуаля, теперь вы можете отправлять те же времена байта (заполните экран ILI9341).
Даниэфф
Солнце 14 мая 2017 г. 10:50 утра
Да, я включил его на страницу сравнения. В основном я говорил о том, что API Thomas L4 SPI может быть расширен для него, просто позвонив с NULL, NULL, чтобы отправить тот же байт, без введения новых методов. Что не так, потому что ему нужны новые методы, поэтому давайте оставим это на данный момент.
victor_pv
Солнце 14 мая 2017 г. 16:18
Даниэфф написал:Да, я включил его на страницу сравнения. В основном я говорил о том, что API Thomas L4 SPI может быть расширен для него, просто позвонив с NULL, NULL, чтобы отправить тот же байт, без введения новых методов. Что не так, потому что ему нужны новые методы, поэтому давайте оставим это на данный момент.
Даниэфф
Пт 16 июня 2017 г., 4:58
Добавлена передача [16] (out, in, count [, обратный вызов]). Out может быть Uint [8 | 16] _t / *Buffer / null; В может быть *буфер / нулевой; обратный вызов не может быть ничего/null/funcptr. Это должно покрывать все варианты использования.
Добавил пример видео+аудиоплеер. Играет со скоростью 27 кадров в секунду на F407, ILI9341, SPI+I2S Nonblocking DMA, SDIO, блокирующее DMA. Пример вывода без звука, потому что мой дерьмовый телефон не может записать звук: http: // danieleff.com/stm32/test/output_no_sound.MP4
(Виктор, я интегрировал большинство ваших изменений, но DMA теперь централизован, пожалуйста, используйте Master для дальнейшего развития)
Добавил пример видео+аудиоплеер. Играет со скоростью 27 кадров в секунду на F407, ILI9341, SPI+I2S Nonblocking DMA, SDIO, блокирующее DMA. Пример вывода без звука, потому что мой дерьмовый телефон не может записать звук: http: // danieleff.com/stm32/test/output_no_sound.MP4
(Виктор, я интегрировал большинство ваших изменений, но DMA теперь централизован, пожалуйста, используйте Master для дальнейшего развития)
Пито
Пт 16 июня 2017 г., 6:40
Существует библиотека под названием ADAFRIT_ILI9341_STM_SPI2, я использовал для использования с MM/BP.
Эта библиотека была изменена для поддержки DMA в Maple Mini Victor в 2015 году.
Будет ли эта LIB работать с общим? (Еще не тестируется).
Эта библиотека была изменена для поддержки DMA в Maple Mini Victor в 2015 году.
Будет ли эта LIB работать с общим? (Еще не тестируется).